Running YOLOv5 on a Microcontroller
November 25, 2024
Running YOLOv5 on a microcontroller is no small task, given the model’s computational requirements (>20MB). In this post, I’ll share how I successfully ran a simplified YOLOv5 model on an ESP32 microcontroller and optimized it for performance and memory constraints, achieving a model size of just 23KB.
- YOLOv5 on Embedded Devices: The Challenge
- Use Case: Screw Type Detection
- How I Simplified the Model
- Lessons Learned
- Conclusion
YOLOv5 on Embedded Devices: The Challenge
YOLOv5 from Ultralytics follows a Backbone, Neck, and Head architecture:
- The Backbone is responsible for extracting features from the input image at different resolutions, scales or levels.
- The Neck combines features from different levels of the backbone.
- The Head generates bounding boxes and class predictions based on the features extracted by the backbone and neck.
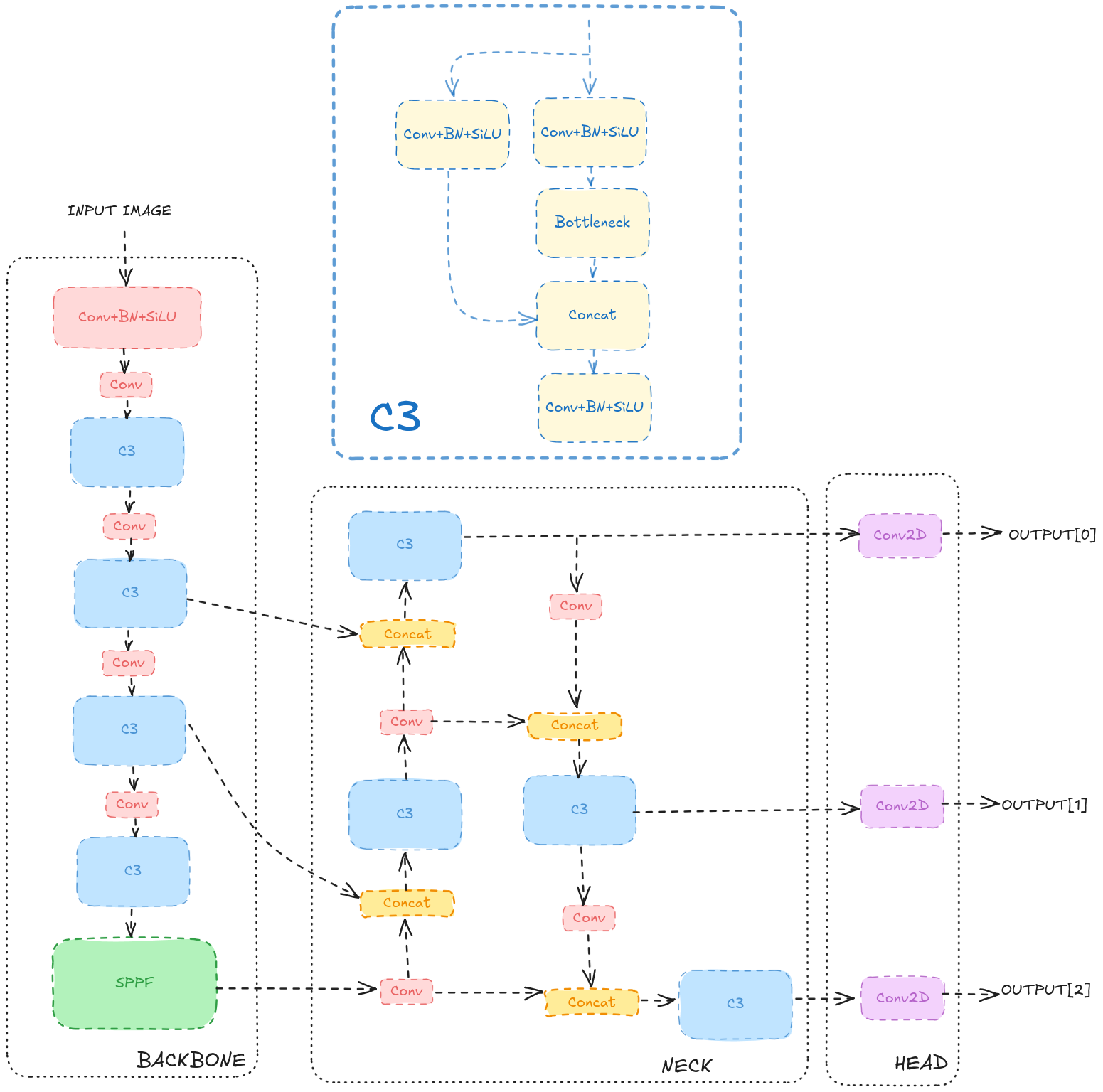
A more detailed architecture can be found in the YOLOv5 documentation.
The model is quite complex and the smallest version from Ultralytics is a few MBs. However, the ESP32 microcontroller has just 4MB of flash memory and 8MB of PSRAM, making it impossible to run the full model without optimizations.
Use Case: Screw Type Detection
The first step to simplifying YOLOv5 was to define a specific use case, with fixed conditions that could be optimized for. I focused on detecting screw types (e.g., “Big,” “Medium,” “Black”) using an ESP-EYE module. The constraints were as follows:
- Images were 96x96 pixels: After some tests, I found that this resolution was minimum to detect the screws with acceptable accuracy and speed on the deployed hardware.
- The camera and screws were at a fixed distance: This allowed me to have fixed sizes, so I didn’t have to look for objects at different scales or levels.

These constraints simplified the problem, making it easier to reduce the model size.
How I Simplified the Model
- Reduce Input Size: Input images were resized to 96x96 pixels, reducing the parameters and memory usage.
- Simplify the Backbone: I reduced the number of layers and filters by trial and error, keeping acceptable accuracy while cutting computational demands.
- Simplify the Head: Removed multi-scale predictions since the object sizes were fixed.
- Quantize the Model: Converted weights and activations from float32 to uint8, reducing memory usage.
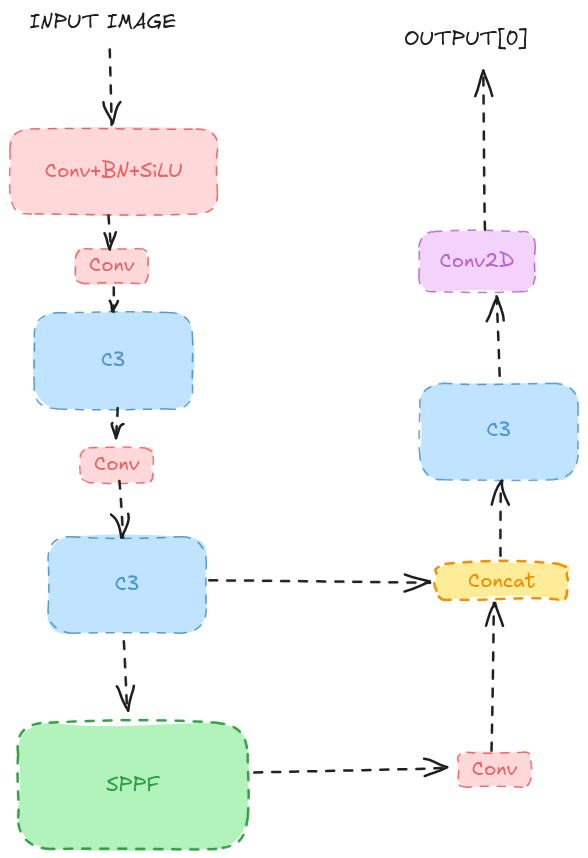
In the picture below, I marked in red the flow of the blocks I keep from the original YOLOv5 model:
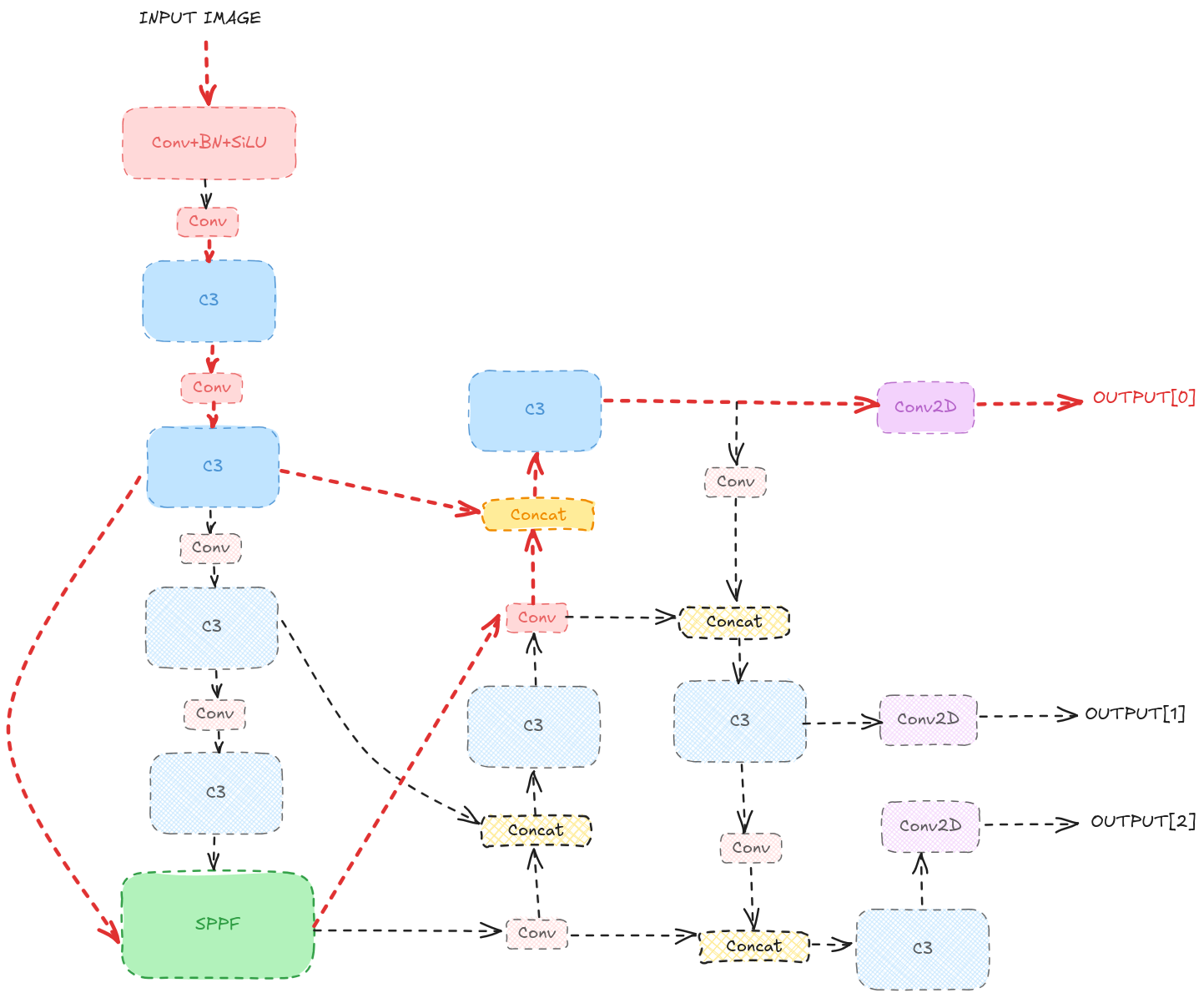
The simplified model had fewer layers and filters, making it suitable for the ESP32 microcontroller.
Result: After these optimizations, the model shrank to a mere 23KB with quantization:
model_format : uint8
params # : 23,066 items (23.70 KiB)
----------------------------------------------------------
input 1/1 : 27.00 KiB, (1,96,96,3)
output 1/1 : 3.38 KiB, (1,432,8)
macc : 6,532,528
weights (ro) : 24,276 B (23.71 KiB)
activations (rw) : 36,864 B (36.00 KiB) (1 segment)
ram (total) : 67,968 B (66.38 KiB) = 36,864 + 27,648 + 3,456
You can reproduce these results using my project repository.
Lessons Learned
- Fixed Scenarios Simplify the Problem: The controlled environment (fixed camera and object size) allowed me to remove unnecessary complexity.
- Quantization is Key: Converting the model to uint8 saved both memory and computational resources, critical for microcontrollers.
- Iterative Testing Works: Simplifying the backbone and head required experimentation, balancing size with accuracy.
Conclusion
By choosing a specific use case, reducing input size, simplifying the architecture, and quantizing the model, I was able to run YOLOv5 on a resource-constrained ESP32 microcontroller. This process demonstrates how deep learning can extend to edge devices, even with strict memory and processing limits. I hope this inspires you to explore similar optimizations for your embedded projects!